GooSeeker是一款强大且好用的页面采集工具,它能帮助网站站长和淘宝店主采集网页上的任何图片、文字、超链接以及表格等各种元素,和其他同类软件相比,该软件具备采集速度快、操作简单、使用方便等优势,无论你是新手还是老用户都能轻松使用,因为它几乎不需要你懂任何编程知识,还修改任何爬虫代码就能实现操作,而且针对新闻、论坛、电商、社交网站、行业资讯、金融网站、企业门户、政府网站等各种网站都可抓取,GooSeeker软件的中文名叫集搜客,和八爪鱼、火车头这类采集软件不同的是,这款软件具有可视化的采集流程,而且它主要是对抓取的数据和爬虫路线进行重点操作,因此该软件能满足更多用户的需求,无论是动态网页还是静态网页,都可以使用这款软件统统收入囊中。
gooseeker爬虫软件使用教程
1、安装好该软件,下图为安装好的界面:
2、点击右上方的“MS谋数台”,弹出如下界面:
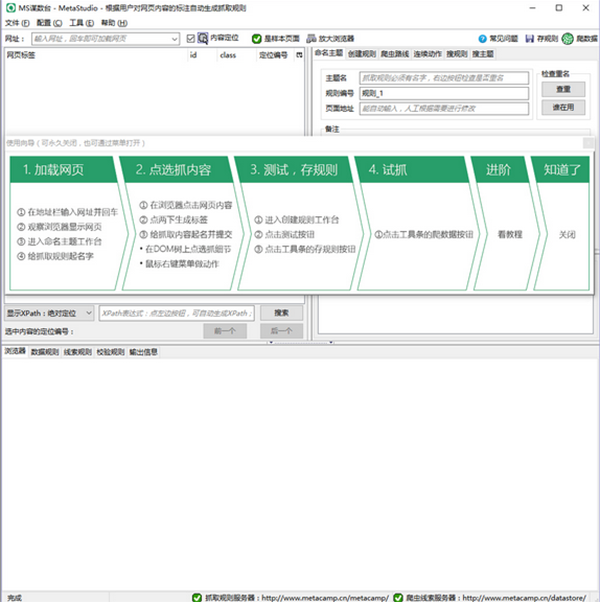
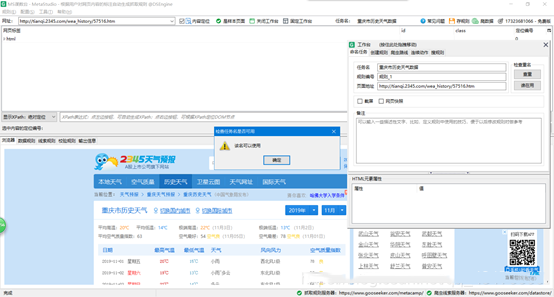
3、在左上方的网址栏输入想要爬取的网站,我这里输入天气网站,并在工作台里面创建任务,进行命名和查重,直到可以使用:
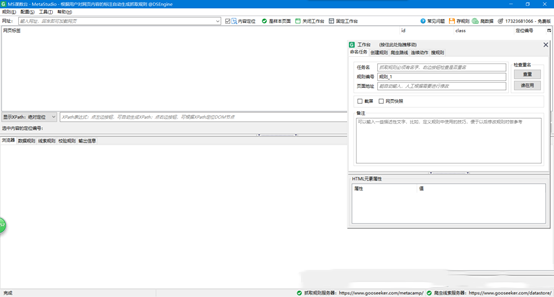
4、在工作台上方标题栏中选择创建规则,选择“新建”并命名,点击确定:
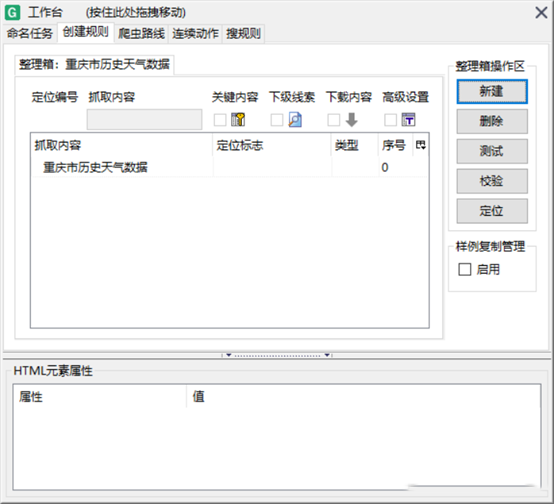
5、点击“抓取内容”中自己的命名的一栏,选中点击右键,选择“添加”,选择“包容”:
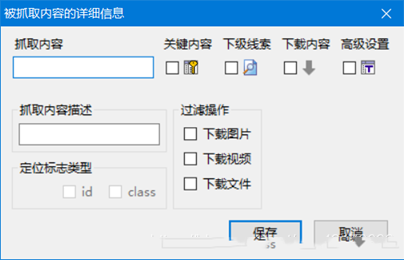
6、输入你想抓取的内容名称并保存,我这里重复此步骤,创建抓取内容“日期”、“最高气温”、“最低气温”、“天气”、“风向风力”、“空气质量指数”,并将“日期”勾选为关键内容:
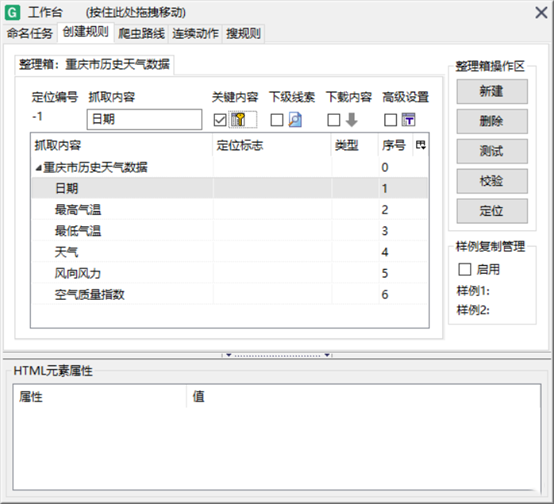
7、在“浏览器”窗口中点击你想要获取的内容,比如现在要获取“日期”,就在“日期”那个区域进行鼠标点击,这时候MS谋数台会自动定位“日期”,即在HTML中结点的DIV结点位置。展开结点,找到text结点,右击鼠标,选择内容映射,然后选择你想要映射至的抓取内容:
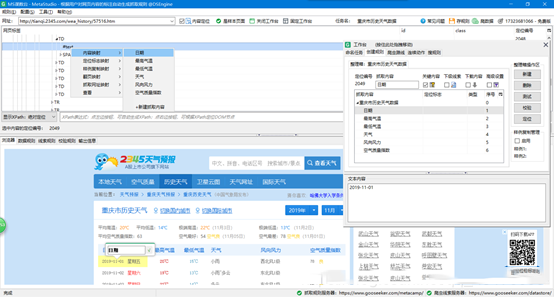
8、重复进行第七步,知道把想要抓取的内容给全部映射:
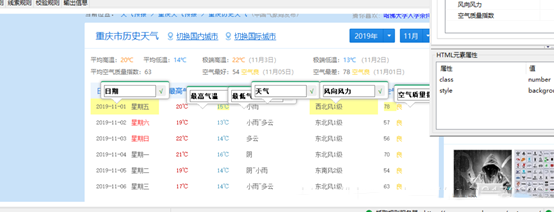
9、创建爬虫路线,点击工作台标题栏中的“爬虫路线”,点击“新建”:
10、创建翻页定位编号,在浏览器中点击上一月,网页会自动定位该文本的结点,右击结点选择“翻页映射”,“作为翻页区”,“线索一”:

11、创建记号定位编号,在游览器中点击上一月,在网页标签里会自动该文本定位的结点,打开该结点,可以看到text属性,右击text(此处只能右击text,不能右击结点),选择 “翻页映射”,“ 作为翻页记号”:
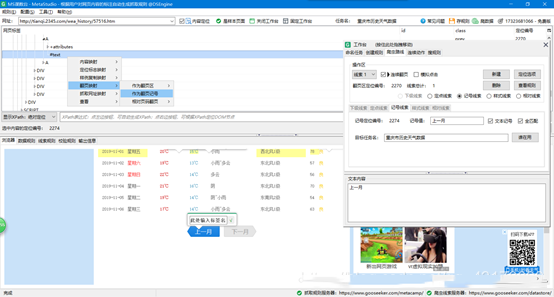
12、创建样例复制映射,点击工作台标题栏里面的新建规则,勾选右方的启用,启动样例复制管理功能:
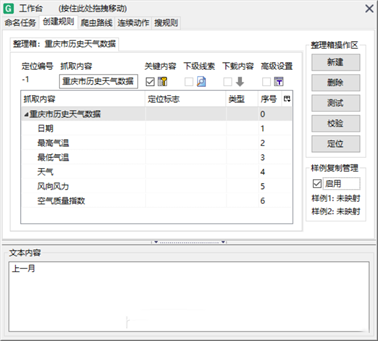
13、分别找到该页面想要爬取的第一条数据的日期栏和第二条数据对应的日期栏的节点,右击第一条数据的日期栏对应的结点,选择“样例复制映射”,“第一个”,右击第二条数据的日期栏对应的结点,选择“样例复制映射”,“第二个”:
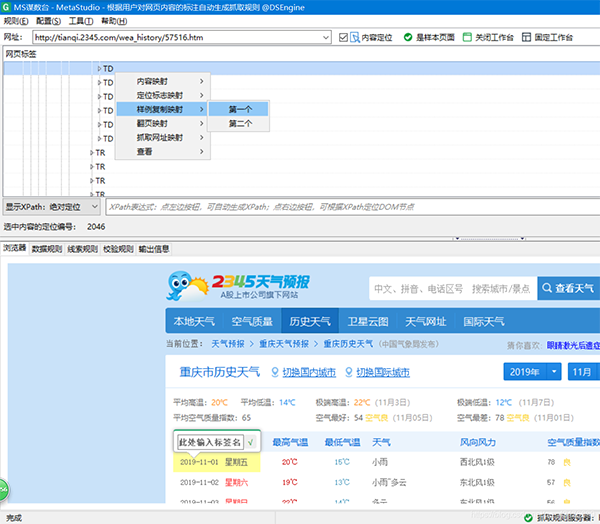
14、点击工作台左方的测试,对当前的规则进行测试:
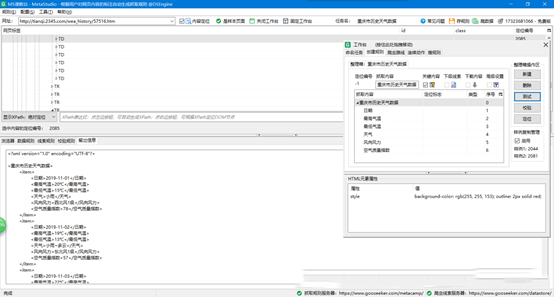
15、当测试爬取内容为想要的爬取内容时就可以保存当前规则了,点击“MS谋数台”右上方的“存规则”即可保存规则,然后可以使用我们创建的规则进行数据爬取了,想要看自己是否保存规则,就在工作台标题栏里面的“搜规则”查看:
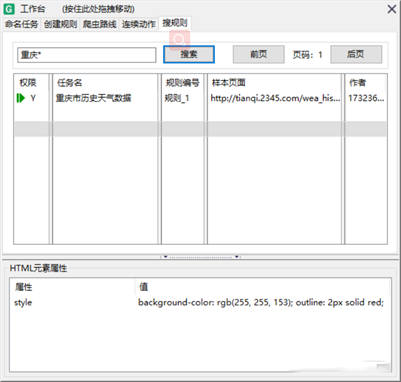
16、打开“DS打数机”,“DS打数机”在Gooseeker浏览器中的右上方,打开“DS打数机”,点击“文件”,“存储路径”,“ 自定义数据的存储路径”:
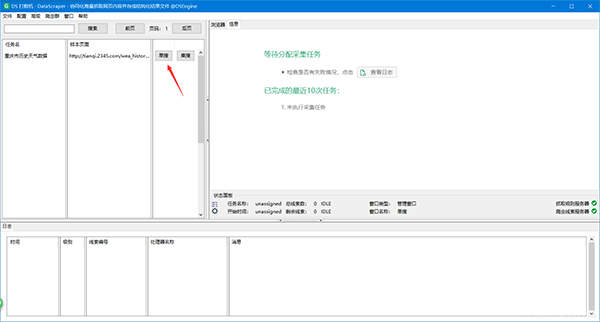
17、点击“单搜”,设置抓取网页数量,即可开始抓取:
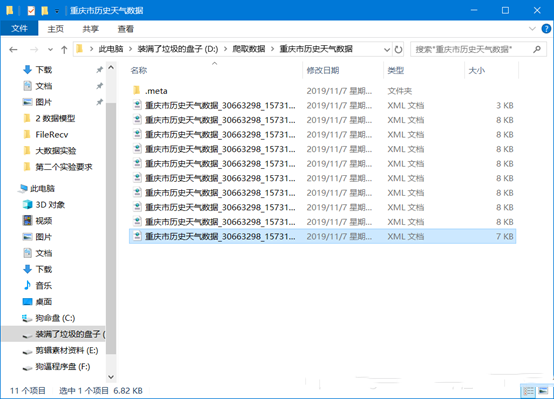
18、然后打开存储地址,然后可以看到爬取的数据以XML文件保存:
19、用EXCEL打开其中一个文件,可以看到爬取的数据集,数据爬取完成:
常见问题
1、网络爬虫状态错误,无法从FAILED状态启动爬虫?
这个报错是说服务器连接失败,失败的时候显示为红色状态,正常是绿色
2、保存信息结构描述文件失败:not writable?
①主题名重复了,换个主题名就行
②“爬虫路线”工作台上,如果有下级线索,也要注意不能与别人重名。都有“查重”按钮,可以检查一下
3、为什么谋数台又打不开了,打数机能打开?
①火狐自动升级后跟爬虫不配套,就不能正常使用了,所以,安装火狐的时候要去工具菜单->选项->高级->更新里设置不检查更新
②下载了更高版本或中国版火狐,里面安装很多插件,可能影响到gooseeker爬虫的正常使用
③电脑安装了360等杀毒软件,会悄悄破坏其他程序,只需禁止其安全防护功能
软件特色
1、直观标注采数据
不用程序思维,不要技术基础,点击想要的内容,软件自动管理所选内容,自动放进整理箱
2、可视化免编程
抓取软件操作简单,完全可视化操作,无需编程基础,熟悉电脑操作即可轻松掌握
3、模板资源套用
在抓取规则的详情页面,您可以仔细考察一个规则的抓取结果是否满足您的需要,如果满足,只需点击“下载”按钮,即可在会员中心一键启动集搜客网络爬虫,抓取到你想要的数据
4、通用网络爬虫
采用功能强大的火狐浏览器内核,所见即所得
5、会员互助抓取
这是爬虫群并行抓取的一种特殊情形,利用这个功能,可以低成本快速汇集海量数据
6、不限深度不限广度
以尽量低的成本获得数据,而且只获取需要的网页内容
7、抓取指数图表
集搜客网络爬虫具有强大的图表数据抓取能力,而且提供一个开发者扩展接口,允许技术基础高的用户用Javascript自定义更高级的网络爬虫动作
8、本地化存储保护隐私
把所有采集结果数据直接存储在用户个人电脑上,便于用户对采集结果数据做各种处理
9、自动登录验证码识别
具有自动登录功能,只需要设置相关参数,就可以控制集搜客网络爬虫定期自动登录相应的账号
11、爬虫群并行抓取
集搜客的并行抓取功能,一方面可以帮助个人解决效率低下的问题,另一方面也促进社区闲散资源的整合利用
12、一键“集搜”启动多爬虫抓取数据
可选择分布式采集的方式,把采集任务分配到多台电脑上执行
13、手机网站数据抓取
使用该软件采集手机网站数据和采用PC网站数据同样简单, 可视化定义抓取规则的过程完全一样
功能介绍
1、集成化图形界面
包括网页结构窗口、工作台、显示窗口等子窗口。选取被抓取内容时,三个子窗口联动,并显示HTML节点的重要属性
2、抓取规则自动生成
指定抓取内容,定义抓取结果存放结构(整理箱),然后将网页内容分别映射给整理箱中的抓取内容,MS谋数台即可自动生成抓取规则
3、原始网页内容纠错
网页的发布者在写网页的时候可能存在语法和词法错误,只要是火狐浏览器能打开的,都能定义抓取规则并进行抓取
4、防屏蔽抓取
有些目标网站可能根据点击行为特征屏蔽网络爬虫的过度访问,集搜客GooSeeker采用技术手段尽量避免被屏蔽
5、清理运行状态
使用ADSL等动态分配地址的部署方式,定期拨号更换IP地址,也可在火狐浏览器上清除cookie和缓存

 无插件
无插件
 360通过
360通过
 腾讯通过
腾讯通过
 金山通过
金山通过
 瑞星通过
瑞星通过






 下载地址
下载地址

 大家都喜欢
大家都喜欢
 用户评论
用户评论